流程术语
概览
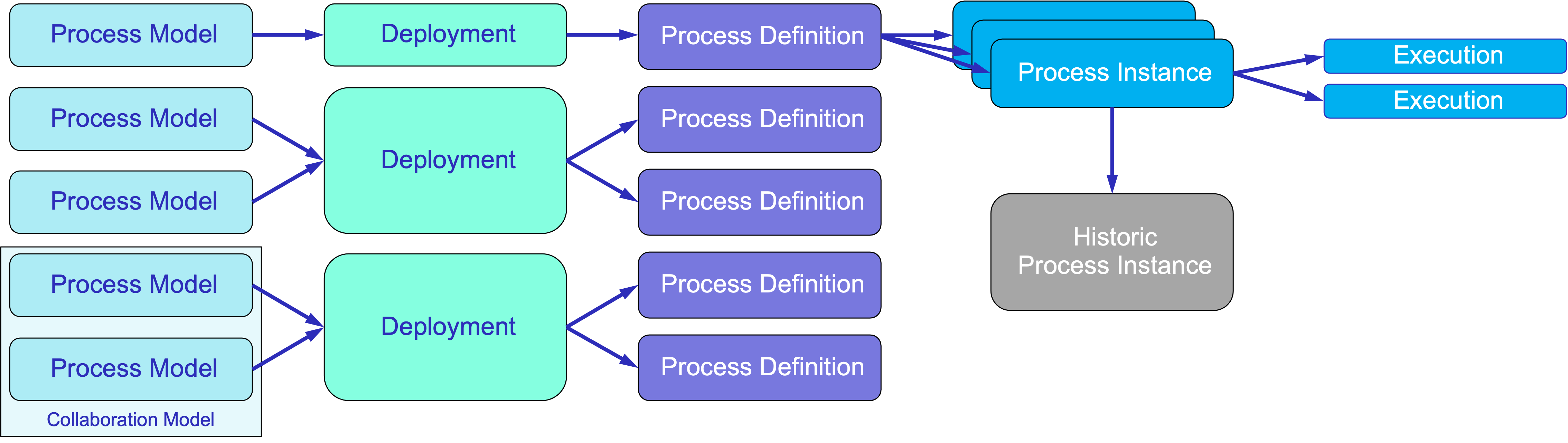
流程模型
在 Jmix BPM 中,流程模型(Process model) 是指业务流程的一种结构化表示,使用 BPMN 2.0 标准通过 XML 格式定义。 BPMN 流程模型的结构由几个关键部分组成,这些部分共同描述了业务流程的行为和流向。
<definitions> 部分是 BPMN XML 文件的根元素。
其中包含了整个流程模型,并为其中定义的各种组件提供了上下文。
这个部分通常包括模型的元数据,例如 XML 命名空间和 schema 地址,
确保文档符合 BPMN 标准。
在 <definitions> 内部,可以看到 <process> 或 <collaboration> 元素。
<process> 元素定义一个单一 流程 及其关联的活动、事件和网关。
这是在对简单业务流程进行建模时最常用的结构。
另一方面,
当多个流程交互时,使用 <collaboration> 元素,
可以对具有不同参与者或实体的多个工作流进行更复杂的表示。
在这种情况下,将创建一个 协作 模型。
模型还包括消息、信号和错误的 事件定义。
最后,<diagram> 部分提供了流程模型的可视化表示,通常使用图形表示法。
由于能直观地展示流程的流向和结构,这部分对人类读者和流程设计人员非常有用。
尽管这个图不会影响流程的执行,但提升了相关人员之间的理解和沟通。
下面是 BPMN 2.0 表示法中的可视化流程模型及其 XML 表示的示例:
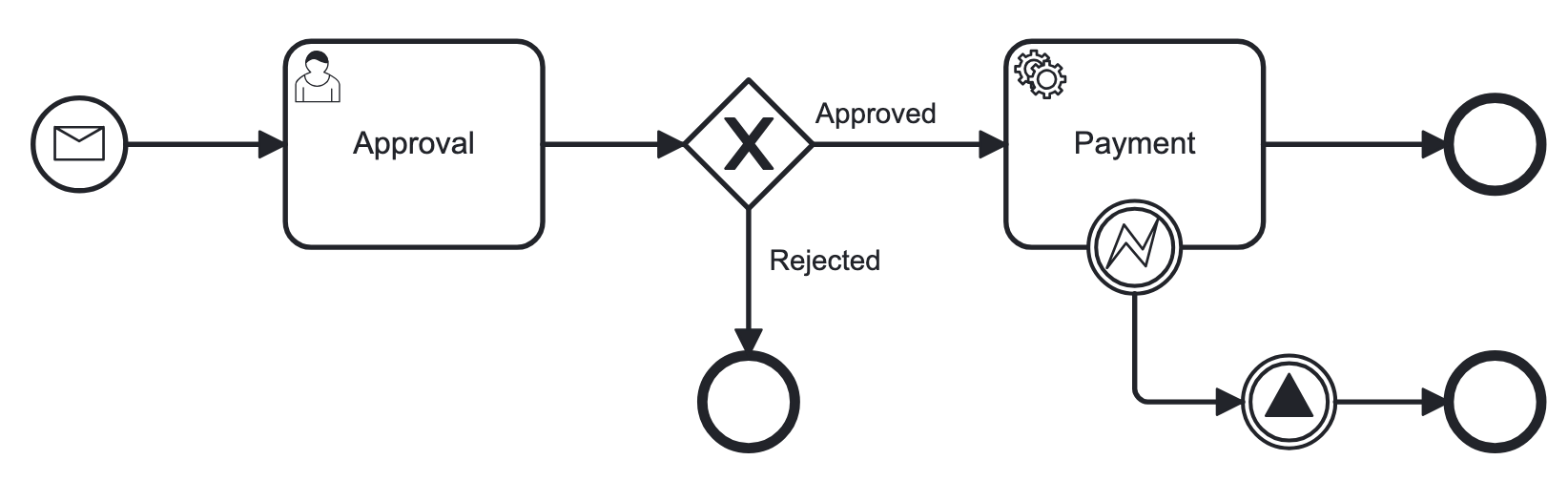
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL" <!--Other namespases.... --> >
<!--Process definition-->
<process id="document-approval" name="Document approval" isExecutable="true">
<!--Process elements-->
<process/>
<!--Event definitions-->
<message id="start-approval-process" name="Start approval process" />
<signal id="payment-failed" name="Payment failed" flowable:scope="global" />
<error id="payment-serice-error" name="Payment serice error" errorCode="900" />
<!--Diagram section-->
<bpmndi:BPMNDiagram id="BPMNDiagram_process">
<!-- Diagram elements -->
<bpmndi:BPMNDiagram/>
</definitions>存储流程模型
在 Studio 中,流程模型的草稿存储在 src/main/resources/process-drafts,
可以部署的模型存储在 src/main/resources/processes。
可以通过 Flowable 应用程序属性 修改流程模型的存储位置, 但是不建议这么做。
As well, you can create atd store drafts at runtime using the Web Modeler.(译者注:web 存储位置 atd store?)
|
Studio 和 Web 应用程序中的草稿存储在不同的位置, 并且不同步,包含不同的模型集。 |
部署对象
部署(deployment) 对象是一个存储各种业务流程资源的容器, 例如,BPMN 流程模型、图片、表单以及其他制件。
业务归档
部署流程时,必须将流程打包为 业务归档(business archive - BAR)。 业务归档是部署到流程引擎的单元, 与 ZIP 文件类似。 可以包含 BPMN 2.0 流程、DMN 规则和任何其他类型的文件。 一般来说,业务归档包含资源集。
部署业务归档时,会扫描其内容,查找扩展名为 .bpmn20.xml 或 .bpmn 的 BPMN 文件。
然后引擎会处理这样的文件,一个文件内也可能包含多个流程定义。
激活 DMN 引擎时,还会解析 .dmn 文件。
|
Jmix BPM 不使用 Flowable 表单。 |
创建部署
在 Jmix BPM 中,可以通过编程方式或使用 UI 功能创建部署。
以编程方式,部署是通过 RepositoryService 服务使用 DeploymentBuilder 接口创建。
资源通过 addClasspathResource、addInputStream 这样方法添加到部署中。
资源添加完成后,调用 deploy() 完成部署:
repositoryService.createDeployment()
.name("My Deployment")
.addClasspathResource("processes/my-process.bpmn") (1)
.addString("greeting", "Hello, world!") (2)
.deploy();| 1 | — 添加 XML 格式的 BPMN 流程模型。 |
| 2 | — 添加一个字符串类型的资源。 |
在 Studio 中,流程会自动部署,请参阅 模型自动部署 部分。 或者可以使用 Studio 的 热部署 功能进行部署。
在 Web 建模器 中,可以手动部署流程。
部署完成后,部署对象将变为只读。 即,其内容在部署后无法更改,从而确保已部署资源的完整性。
在部署时,Flowable 会解析部署中包含的 BPMN XML 文件。 对于每个完成解析的 BPMN 文件,Flowable 会创建一个或多个流程定义。 每个流程定义都对应一个 BPMN XML 中的定义。
访问已部署资源
如需在运行时访问已部署资源:
// 已部署资源列表
List<String> resourceNames = repositoryService.getDeploymentResourceNames(deploymentId);
// 获取特定资源
InputStream resourceStream = repositoryService.getResourceAsStream(deploymentId, "my-resource.txt");删除部署
可以使用 RepositoryService 删除部署对象:
// Specify the deployment ID you want to delete
// Replace with your actual deployment ID
String deploymentId = "yourDeploymentId";
// Delete the deployment
// The second parameter indicates whether to cascade delete process instances
repositoryService.deleteDeployment(deploymentId, true);第一个参数是部署 ID,可以在创建部署时记录或通过查询已有部署来获取该 ID。
第二个参数(true 或 false)决定是否级联删除与该部署关联的所有流程实例。
如果设置为 true,则删除从这个部署创建的所有激活和历史流程实例。
如果级联删除设置为 false,
则不会删除该部署关联的任何流程实例。
也就是说,虽然不能用流程定义生成新实例,
但已有实例在系统中保持不变。
|
可以在 流程定义详情(Process Definition Detail) 视图中手动删除特定的部署。 但请记住,此操作会同时删除已部署的 所有 流程定义。 |
流程定义
创建流程定义
流程定义无法直接创建, 而是在部署过程中创建的。
每个 流程定义 都与一个特定的 部署 相关, 部署是一个或多个流程定义和相关资源的容器。
如需查看部署到引擎的流程定义列表, 可通过 BPM→ 流程定义视图 查看。
激活和挂起
流程定义有两种状态:激活(active) 和 挂起(suspended)。
-
激活状态:在此状态下,可使用该流程定义中规定的结构创建和执行流程。
-
挂起状态:在此状态下,无法启动该定义的新实例, 但是已经在运行的现有实例可以继续运行,直到完成或终止。
状态转移:
// Suspending a process definition
repositoryService.suspendProcessDefinitionByKey(processDefinitionKey);
// Activating a suspended process definition
repositoryService.activateProcessDefinitionByKey(processDefinitionKey);另外,也可以通过 ID 挂起或激活流程定义。
流程定义的版本
在部署期间, 流程引擎在将 流程定义 存储到数据库之前会为其分配一个版本号。 因此,流程定义是带版本的,同一流程的多个版本可以同时存在。
id 属性设置为
{processDefinitionKey}:{processDefinitionVersion}:{generated-id},
其中 generated-id 是一个唯一的数字,
以确保群集环境中流程定义缓存 ID 的唯一性。
|
流程模型中的 |
访问流程定义
运行时访问流程定义:
// Querying for all process definitions in deployment
List<ProcessDefinition> processDefinitions = repositoryService.createProcessDefinitionQuery()
.deploymentId(deploymentId)
.list();
// Querying for all versions of the process definition
repositoryService.createProcessDefinitionQuery()
.processDefinitionKey(key)
.list();
// Querying for the latest version of the process definition
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.processDefinitionKey(key)
.latestVersion()
.singleResult();删除流程定义
如需删除流程定义,则需要删除其关联的部署对象。 参阅 删除部署。
流程实例
流程实例(process instance) 表示业务流程的运行实例。封装了特定 流程定义 的执行过程,并有自己的状态和数据。
流程实例生命周期
流程实例的生命周期有几个阶段, 表示流程运行中的各种状态和转换。
创建
当启动流程定义的一个新实例时,将创建流程实例。
这可以使用 RuntimeService 的 startProcessInstanceByKey 或 startProcessInstanceById 方法实现。
在这个阶段,可以将初始变量传递给实例:
// Example variable for the process
Map<String, Object> variables = new HashMap<>();
variables.put("employeeId", "12345");
ProcessInstance processInstance = runtimeService
.startProcessInstanceByKey("my-process", variables);ProcessInstanceBuilder builder = runtimeService.createProcessInstanceBuilder()
.processDefinitionKey("myProcess")
.businessKey("holidayRequest-123")
.variable("employeeId", "12345")
.start();
ProcessInstance processInstance = builder.start();激活状态
创建后,流程实例将进入 激活(active) 状态, 开始执行流程定义中定义的任务。 实例最终会完成 BPMN 模型中定义的各种任务、事件和网关。
查询流程实例是否处于活动状态:
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(processInstanceId)
.active()
.singleResult();如果流程实例已挂起,则可以将其激活。
runtimeService.activateProcessInstanceById(processInstanceId);挂起状态
流程实例可以被挂起,挂起时,流程会暂停执行,但不会终止。 于是可以在不丢失实例当前状态的情况下进行维护或更新。 挂起时,不会执行任何任务,但仍可查看已有任务。
可以使用 流程实例详情(Process Instance Detail) 视图或以编程方式挂起流程实例:
runtimeService.suspendProcessInstanceById(processInstanceId);查询流程实例是否已经挂起:
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(processInstanceId)
.suspended()
.singleResult();完成
当流程实例中的所有任务和事件都已完成时,则该流程已完成。 但是流程实例没有特殊的 完成 状态。 此时,会删除已完成的流程实例, 并创建对应的 历史流程实例。 可以查询该历史记录用于报表和审计目的。
在流程执行期间设置的任何变量都最终确定并存储在历史记录中, 支持在完成后进行检索和分析。
实例完成后,流程引擎可能会触发 BPMN 模型中定义的特定事件, 如结束事件或信号, ,以便在系统内启动进一步的操作或通知。
|
没有方法可以直接对流程实例本身调用“完成”操作。 而是,需要处理任务并确保满足 BPMN 模型中定义的所有条件来完成流程。 |
终止
流程实例也可以在完成之前 终止(terminated)。 将会强制停止流程的执行并释放与其关联的所有资源。 已终止的实例不再处于激活状态,无法恢复。
如果终止的流程实例是较大工作流的一部分, 则终止该流程可能会影响父流程的完成状态。
runtimeService.deleteProcessInstance(processInstanceId, "Reason for termination");|
在 Flowable 流程引擎中, 在谈及流程实例时,终止(termination) 和 删除(deletion) 的概念是等效的。 |
只有当流程实例没有正在执行任务时,才能删除该实例。 如果存在激活的任务, 则在尝试删除之前,需要确保任务已完成或实例处于 等待状态。
如果流程实例正在执行异步任务,则可能会出现 并发更新异常(concurrent update exception)。 发生这种情况是因为流程引擎使用了乐观锁机制, 即一次只能有一个事务可以修改数据库中的一行。 如果我们在尝试删除一行数据时,另一个事务在尝试更新或删除该行,则会引发异常。
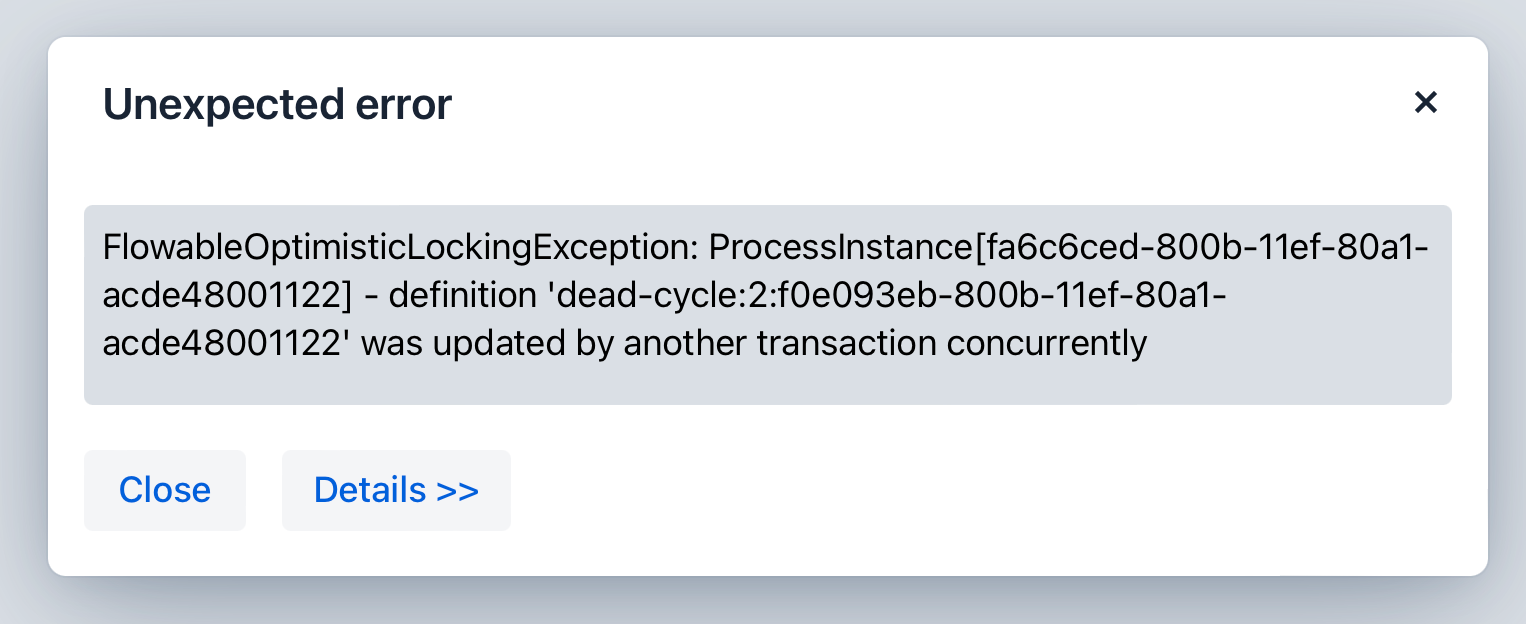
删除流程实例时,流程引擎不会触发与删除操作关联的任何监听器事件。 也就是说,无法通过监听器实现与删除事件相关的自定义行为。
访问流程实例
在运行时访问流程实例:
// Querying for all instances of a specific process definition
List<ProcessInstance> instances = runtimeService.createProcessInstanceQuery()
.processDefinitionKey(key)
.list();
// Querying for a specific process instance by ID
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(instanceId)
.singleResult();流程实例属性
| 属性 | 描述 |
|---|---|
Process Instance ID |
流程实例的唯一标识符 |
Business Key |
流程实例在业务级别的标识符(可选) |
Parent ID |
如果此字段为 |
Process Definition ID |
该实例对于的流程定义 ID |
Start Time |
流程实例启动的时间戳 |
End Time |
流程实例完成的时间戳 |
Duration |
流程实例执行的时长 |
State |
流程实例的当前状态。例如,运行中(running)、挂起(suspended)、完成(completed)。 |
Variables |
与流程实例相关的变量 |
执行过程
一个 执行过程(execution) 对象表示流程实例中的一段 “执行路径”。 这是是 Flowable 引擎中的一个基本概念, 支持在流程通过各种活动时跟踪流程的当前状态和流向。
|
流程实例 vs. 执行过程:
|
执行过程以分层树结构进行组织。 流程实例也被认为是最顶层的一个执行过程, 可以包含表示子流程或并行活动的子执行过程。 即使在简单的流程中,流程引擎也会在流程实例下创建一个执行过程。
方法 getParentId() 可以查询检索父执行过程的 ID,
在父子执行过程之间建立明确的关系,
对于管理复杂的工作流程非常重要。
子执行过程可以保存其上下文中的 局部变量。
访问执行过程
查询特定流程实例的子执行过程:
List<Execution> childExecutions = runtimeService.createExecutionQuery()
.processInstanceId(processInstanceId)
.list();删除执行过程
在不删除整个已激活流程实例的情况下, 无法删除该实例的执行过程。 执行过程与父流程实例是紧耦合关系, 共同表示该实例的当前状态。
对于多实例任务,
可以使用 deleteMultiInstanceExecution() 方法删除与多实例活动相关的所有执行过程,
但这仍然与父流程实例的上下文相关。
// Replace with your execution ID
String executionId = "yourExecutionId";
// Set to true if you want to mark it as completed
boolean executionIsCompleted = true;
runtimeService.deleteMultiInstanceExecution(executionId, executionIsCompleted);|
确保尝试删除的执行过程未处于激活或无法删除的状态。 如果存在并发事务或依赖项,则可能会产生异常。 |
执行过程属性
执行过程与流程实例的属性相同。 参阅 上面的表格。
任务实例
任务实例(task instance) 表示流程中任务的特定实例。 当流程执行到达用户任务、服务任务或任何其他类型的任务时,将创建一个该任务的实例。 任务实例可用于跟踪和管理用户或系统对任务的执行情况。
独立任务
可以创建不直接绑定到特定流程实例的独立任务。 该功能为各种场景中的任务管理提供了额外的灵活性。 示例:
Task newTask = taskService.newTask();
newTask.setName("Standalone Task");
newTask.setAssignee("userId"); // Assign to a user
taskService.saveTask(newTask);访问任务实例
任务实例可以通过 TaskService API 编程式访问。
示例:
//Getting task by ID
Task task = taskService.createTaskQuery().taskId(taskId).singleResult();
//Getting a list of tasks, assigned to user
List<Task> tasks = taskService.createTaskQuery().taskAssignee("userId").list();删除任务实例
从技术上讲,可以通过编程方式删除任务:
taskService.deleteTask(taskId, "Reason for deletion");|
但是,删除任务会有多种可能导致关联的流程出现问题。 因此,删除任务时必须谨慎, 通常需要指定查询条件以避免意外的数据丢失。 |
任务实例属性
| 属性 | 描述 |
|---|---|
Id |
任务实例的唯一标识符 |
Execution Id |
任务关联的执行过程的 ID |
Process Instance Id |
任务所属的流程实例的 ID |
Process Definition Id |
任务关联的流程定义的 ID |
Task Definition Id |
该任务基于的任务定义的 ID |
State |
任务的状态。例如,已创建(created)、已分配(assigned)、已完成(completed) |
Name |
BPMN 模型中该任务的名称 |
Description |
任务的描述,提供额外信息 |
Task Definition Key |
在查询时引用任务定义的键值(等于流程模型中的参数 |
Owner |
任务所有人的标识符 |
Assignee |
任务执行人的标识符 |
Delegation |
任务代理的标识符 |
Priority |
该任务的优先级,影响其处理顺序 |
Create Time |
创建任务的时间 |
In Progress Time |
任务工作的开始时间 |
In Progress Started By |
开始处理该任务的用户标识符 |
Claim Time |
用户领取任务的时间 |
Claimed By |
领取该任务的用户标识符 |
Suspended Time |
任务挂起的时间(如果适用) |
Suspended By |
挂起该任务的用户标识符 |
In Progress Due Date |
在任务进入处理后,到完成此任务的截止日期 |
Due Date |
该任务必须完成的截止日期 |
Category |
该任务的类别或分类 |
Suspension State |
任务状态,已挂起或已激活 |
流程变量
在 BPMN 中,流程变量表示在执行流程实例期间使用的数据。 流程变量是信息容器,可以影响流程的流向, 可以存储中间结果,或者为任务和活动提供输入。
变量可在表达式中使用,例如,在排他网关中选择正确的传出顺序流。 在服务任务中,可以在调用外部服务时使用, 例如,为调用稳步服务提供输入或存储输出结果。
持久化流程变量
与常规 Java 变量不同,流程变量是由流程引擎管理的实体。 引擎在流程启动时, 或者定义和初始化新变量时都会创建流程变量的实例。
因此,流程变量实际上是容器,存储已知 Java 类型的值。
流程变量的类型
在 Jmix BPM 中,支持的流程变量类型有:
-
字符串(String)
-
多行字符串(Multiline string)
-
小数(Decimal)
-
整数(Number)
-
布尔值(Boolean)
-
日期(Date)
-
时期时间(Date with time)
-
实体(Entity)
-
实体列表(Entity list)
-
文件(File)
-
平台中的枚举(Platform enum)
-
对象(Object)- 无法在流程表单中使用
这里的实体仅考虑在数据模型中定义的 Jmix 实体。
当持久化这种类型的变量时,流程引擎在数据库实际存储的是这样格式的字符串:
<entity-name>."<UUID>"",示例:
jbt_User."60885987-1b61-4247-94c7-dff348347f93"
因此,当流程使用这个变量时,会从数据库读取实际的实体。
|
使用实体列表类型的变量时,请注意列表的大小有 4000 字符的限制。 假设一个实体需要 50 个字符,则列表中仅能存储大约 80 个实体。 如果流程变量的长度超过该限制,则在持久化时会发生异常。 但是,可以在事务边界内使用支持更多字符的变量,而不需要持久化。 另外,也可以使用 transient 变量。 |
Transient 变量
Transient 变量的行为与常规变量类似,但是不持久化。通常,transient 变量用于更复杂的场景中。如有疑问,那么还是使用常规流程变量。
使用流程变量
可以在启动流程时将变量传递到流程实例中:
ProcessInstance startProcessInstanceByKey(String processDefinitionKey, Map<String, Object> variables);可以在流程执行期间添加变量。
例如,通过 RuntimeService:
void setVariable(String executionId, String variableName, Object value);
void setVariableLocal(String executionId, String variableName, Object value);
void setVariables(String executionId, Map<String, ? extends Object> variables);
void setVariablesLocal(String executionId, Map<String, ? extends Object> variables);还可以获取变量值,如下所示。
请注意,TaskService 中也存在类似的方法。
也就是说,任务(与执行过程一样)可以有仅在任务持续时间内 “存活” 的局部变量。
Map<String, Object> getVariables(String executionId);
Map<String, Object> getVariablesLocal(String executionId);
Map<String, Object> getVariables(String executionId, Collection<String> variableNames);
Map<String, Object> getVariablesLocal(String executionId, Collection<String> variableNames);
Object getVariable(String executionId, String variableName);
<T> T getVariable(String executionId, String variableName, Class<T> variableClass);变量经常在 Java 委托、表达式、执行监听器、任务监听器、脚本等场景中使用。 在这些场景中,还可以访问当前执行过程或任务对象, 以便设置或查询流程变量。 最简单的方法是:
execution.getVariables();
execution.getVariables(Collection<String> variableNames);
execution.getVariable(String variableName);
execution.setVariables(Map<String, object> variables);
execution.setVariable(String variableName, Object value);|
以上方法也都有带 "local" 的类似方法。 |
